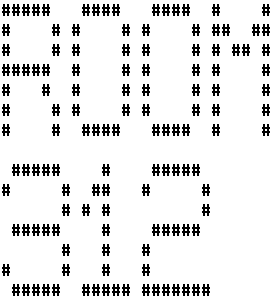
【功能】
產生大型的字體印出
【語法】
banner strings
【說明】
banner 指令會產生 strings 的放大字體,從標準輸出印出。strings 的長度最多為 10 個字元,若 strings 中有空白字元存在,則會分成不同的段落印出,除非使用引號將 strings 包含。
【範例】
1. 列印大型字體的 room 312:
| $ banner room 312 |
|
由於二個字串間有空白字元隔開,故這個指令的輸出結果是 'room' 的字串在上半部,'312' 字串在下半部。
2. 列印大型字體的 room 312 在同一行上:
| $ banner 'room 312' |
|
在 room 312 的前後加上引號,可使輸出的結果強制放在同一行上。
3. 將大型字體輸出到印表機上:
banner PROJECT | lp
4. 將大型字體的 Good Day 送到指定的終端機:
banner 'Good Day' > /dev/tty11
【功能】
提供一個提醒工作要項的服務
【語法】
calendar [-]
【說明】
當我們使用 calendar 指令時,calendar 指令會去尋找使用者啟用目錄下的 calendar 文字檔案,找出日期為今天及明天的行事曆然後印出。「明天」對於星期六而言是指下個星期一,而非星期天。
注意:若遇到特定假日時並不會自動找出下個工作日。
calendar 文字檔案中的資料可由使用者直接以 vi 等編輯程式進行修改或增加內容。
資料檔在每行前端必須是日期,例如 1 月 10 號的格式可為 Jan.10、january 10 或 1/10 等(但不可為 10/1 這種歐洲所使用的格式),在日期之後才是工作要項或說明應該處理的事件使用者可將此一指令加到 .profile 之中,使以後每次進入系統時,可自動提醒今天、明天的重要事件。
【選項】
| 選 項 | 說 明 |
| - | 若任一位使用者在他啟用目錄下有calendar 檔案者,將自動產生郵件去通知。 |
★註:所有的選項是在 SVR4 版本時才開始提供。
【範例】
1. 查詢預定的工作項目:
2. 要求系統提醒每一位使用者有設定 calendar 檔案者。
$ calendar -
【功能】
對資料進行排序的處理
【語法】
sort [-cmu] [-ooutput] [-ykmem] [-zrecsz] [-dfiMnr][-btx] [+pos1 [-pos2]] [files]
【說明】
sort 指令可對資料進行排序的處理,從檔案 ~F5;files~I; 或標準輸入讀取,處理時是以行為單位依字元的大小排序後,將結果送到標準輸出。
注意:排序的方法是對整行的資料做比較,且比較時是以字元在電腦系統中所使用的數字代碼來表示大小,如 ASCII 是以數字字元的代碼最小,接著是英文的大寫字母,最後是小寫字母的代碼最大。
排序的選項可控制排序後的結果是以指定某一欄位的內容進行排序或刪除重複的資料行或是以相反的次序輸出結果。若讀取的資料檔不只一個時,sort 指令的功能可視為排序及合併二個功能。
若檔案 files是 '-' 字元時,則從標準輸入讀取資料。
【選項】
| 選 項 | 說 明 |
| -c (check) | 檢查資料檔是否已按照次序排列。 |
| -m (merge) | 進行多檔案合併的工作,使處理時間縮短。必須在各資料檔內容已按大小排序時才可使用。 |
| -u (unique) | 消除重複的資料,對有相同排序欄位的行只保留一行。 |
| -ooutput (output) |
將排序後輸出的資料放到檔案 output,output名稱可與輸入資料檔案 files 的名稱相同。 |
| -ykmen | 為提高排序速度,可指定主記憶體的空間處理排序的工作,kmem是要求使用的記憶體大小,以 kilobytes 為單位。 若無給予kmem 引數指定要求的記憶體空間大小,則是以預設值處理。若發現空間不足夠時會自動去要求更大的空間。 當可使用的記憶空間小於要求的數量時,則系統會給予目前能提供最大的可使用空間,反之kmem 若小於系統每次處理的最小單位時,則設定為最小的處理空間(-y0 可強迫使用最小的可處理空間;而 -y 選項在無引數時,則會自動使用最大的可用空間)。 |
| -zrecsz (size) | 從輸入的資料檔讀取一行資料進行排序時,若該行的長度大於預設的緩衝區(buffer)長度時,則 sort 指令會自動停止執行,這時應使用 -zrecsz 選項,指定緩衝區的大小(以 byte 為單位)。 |
★ 註:選項 -z 是在 SVR4 版本時才開始提供。
| 選 項 | 說 明 |
改變排序時比較法則的選項: |
|
| -d (dictionary) | 依照字典使用的先後次序做為比較的規則,只有文字、數字及空白有效。 |
| -f (fold) | 在比較時要求不考慮大小寫的區別,例如將 'a' 與 'A' 視為相同的字元。 |
| -I (ignore) | 不處理 ASCII 中無法印出的字元。 |
| -M (month) | 根據月份的縮寫名稱進行比較。 sort 指令會先跳過行的前端空白字元(有如使用了 -b 選項),找出前 3 個字母轉成大寫後進行比較,比較的順序是 JAN(一月)最小,FEB (二月)次之,其餘依此類推,DEC(十二月)最大。 |
| -n (numeric) | 排序時以數字字串的數值來排序。 sort 指令會先跳過每行前端的空白字元(如同使用了 -b 選項),找出數字字串,數字字串中可包含負號及數字字元、小數點。但是對科學符號如 1.5E6則無法正確的處理(可正確辨識的字串如 -10、0.552、20.88等)。 |
| -r (reverse) | 使排序的輸出結果是由大到小(預設的結果是由小到大)。 |
指定排序欄位(sort key)的選項: |
|
+pos1 |
排序欄位的開始位置是跳過該行中 pos1 個欄位。 pos1 的形式可為 m.n 表示,代表跳過 m 個欄位後再跳過 n 個字元才開始比較,若 n 省略則表示 0(亦即從第 m+1 個欄位的第 n+1 個字元開始)。 |
-pos2 |
排序欄位的結束位置是在第 pos2 個欄位為止(該選項省略時表至該行的尾端)。pos2 的形式可為 m.n 表示,代表跳到 m 個欄位後再跳過 n 個字元為止,若 n 省略則表示 0(亦即到第 m+1個欄位的第 n 個字元為止)。 |
-b (blank) |
忽略排序欄位前端的空白字元,常用來改變m.n 中 n 的位置。 |
-tx |
以 x 字元做為欄位間的分隔字元,若在資料檔中有 2 個連續的 x 字元則代表一個空的欄位(預設的 x 字元是空白字元)。 |
★註:選項 -M 是在 SVR3 版本時才開始提供。
【範例】
1. 對檔案進行排序:
sort -o name name
sort 指令會從檔案 name 讀取資料,經過以行為單位的比較、排序等處理後再寫入檔案 name 內(由 -o 選項指定)。
2. 檢查檔案內容是否有按照順序排列:
結果為輸入的 score 檔案的資料內容並無按照順序,故 sort 指令產生 'disorder' 字串的警告訊息。
3. 以數值方式進行排序:
sort -n +4 -6 exp.dat
若檔案 exp.dat 的內容是許多以空白字元所分隔的數值資料,則可指定 -n 選項要求以數值方式比較。
'+4 -6' 是表示只以第 5 及第 6 欄做為比較的欄位。
4. 以相反的順序排序:
sort -r -u name
從檔案 name 讀取資料,經過排序後以相反的順序由大到小(-r 選項)送到螢幕輸出,而 -u 選項則使重複的行只輸出一次。
【功能】
檢查拼字上的錯誤
【語法】
spell [-v] [-b] [-x] [-l] [+local_file] [files]
【說明】
對檔案 files 中所有的單字,spell 指令都會去檢查是否在字典檔中有相同的字,若無則視為拼字錯誤然後從標準輸出印出這些可能的錯字。
若無給予 files 檔案名稱,則會從標準輸入讀取資料,使用者可利用 spell指令來檢查文件檔案中可能拼錯或打字錯誤的字。
【選項】
| 選 項 | 說 明 |
| -v(verbose) | 列出輸入資料有那些單字不在字典檔中,但加上字首、字尾的變化後,可符合字典中的字。 |
| -b(british) | 以英式英文的拼字做為檢查的標準。 |
| -x | 將輸入的資料中每個字仔細分析並印出。 |
| -l | 處理每一個引入檔(include files)。預設的情形為,spell 指令會讀取 troff文件檔案中的引入檔,但不包含以 /usr/lib 開始的檔名。 |
| +local_file | 在local_file 中的字不被視為拼字錯誤,亦即使用者自己所定義的正確拼字。local_file 中的格式必須是每行一個字,且依字母的順序由 a 到 z,如同使用 sort 指令排序後的結果(先是大寫字母、然後是小寫字母),否則不會被接受。 |
★註:選項 -l 是在 SVR3 版本時才開始提供。
【範例】
1. 要求以英式的拼字方式檢查:
檔案 check 中僅有兩個單字,所代表的意義相同,一為美式拼字,另一為英式拼字。
經過 spell 指令檢查後發現 colour 為不在標準的字典檔中,故印出 colour 表示可能不正確。
而第二個 spell 指令則是使用 -b 選項要求以英式拼字方式檢查,故 colour 不會印出。
2. 檢查字尾的變化:
| $ cat paper | |
| After considerable modification this became the now largely accepted concept of "plate tectonics," explaining much of what is observed regarding our dynamic planet. | |
| $ spell | -v paper |
| +ed | accepted |
| +er | After |
| +able | considerable |
| +ing | explaining |
| +ly | largely |
| -y+ication | modification |
| +d | observed |
| +ing | regarding |
| +s | tectonics |
【功能】
將權力轉換為指定的使用者
【語法】
su [-] [name [arg...]]
【說明】
su 指令的功能是將使用權力轉換成指定的使用者,如同直接以使用者name 簽入系統,而不必退出系統後重新簽入。若無給予指定的使用者名稱則系統預設為 root(超級使用者)。下 su 指令後,須輸入密碼才可進行轉換,除非是以超級使用者的名稱簽入才不受此限制。su 指令會去執行新的 shell 程式,並改變真實及有效的使用者、群識別碼,成為被轉換的使用者。若要恢復原來的使用權則可結束轉換,結束時可鍵入 <Ctrl-D> 或是下 exit 指令離開新的 shell。
【選項】
| 選 項 | 說 明 |
| - | 使環境變數全部設定與name 使用者相同。處理的方式是先執行 /etc/profile 再執行name 使用者啟用目錄下的.profile檔案。預設的情形是,除了 PATH 變數外,其餘的環境變數維持不變。 |
| -c cmd (command) | 轉換成別的使用者去執行命令 cmd 後,立即恢復為原來的使用者。 |
| -r (restricted shell) | 轉換成別的使用者時所執行的 shell 程式是受限制的 shell,能使用的功能較少。 |
【範例】
1. 轉換成超級使用者:
su root 或 su
2. 轉換成使用者 bean,並重設環境變數與 bean 使用者所定義的相同:
su - bean
3. 轉換成使用者 bean 後只執行一個命令並立即結束:
su - bean -c "rm jan.dat"
【功能】
將標準輸入所傳送來的資料送往標準輸出,並複製一份存放到file 中。
【語法】
tee [-i] [-a] [file]...
【說明】
tee 指令常使用在記錄命令的執行結果是否正確。
如在重新導向時將前一個指令輸出的結果存放到檔案 file中,並送到下一個指令的輸入。
【選項】
| 選 項 | 說 明 |
| -i (ignore) | 忽略中斷訊號。 |
| -a (append) | 以附加到檔案 file 尾端的方式而非重新寫入。 |
【範例】
1. 在傳送時存放過程到檔案:
ls -l | tee directory | lp
列出目前目錄的內容,然後送到印表機中,在傳送時存放一份資料到檔案 directory 內。
2. 在傳送的過程中存放過程到檔案的尾端:
grep "city" name.dat | tee -a city.lst | lp
取出 name.dat 檔案中有 city 的行,附加到 city.lst 檔案的尾端,以及送到印表機印出。